
[django에 AI 더하기] NLP가 살짝 가미된 워드클라우드 만들기
django + Vue.js를 이용해 게시글을 워드 클라우드로 보여주는 방법을 요약하였습니다.
따라 하기 쉽게 작성하였으며, 각자 개발 환경에 맞게 적용하시면 되겠습니다.
NLP와 워드 클라우드가 핵심이라기보다는 이것을 어떻게 django에서 Vue.js로 서빙해 알맞은 서비스를 만들지 고민하였습니다.
본 글에 오류가 있다면 편하게 알려주세요:) 모든 피드백과 질문을 환영합니다.
🔹 워드 클라우드란?
워드 클라우드는 여러 문자열 데이터를 가공하여 키워드를 보여주는 그림이다. 일반적으로 중요한 단어를 크고 강조된 방식으로 보여주어 원본을 읽지 않더라도 내용 파악을 빠르게 하게끔 도와준다.

🔹 사용한 KR-WordRank NLP 간단 설명
워드 클라우드를 만드는 방법은 '키워드를 가중치로 분류하기(토큰화)', '워드 클라우드 그리기' 이렇게 두 파트로 구분할 수 있다. 가장 간단히 키워드를 가중치로 분류하는 방법은 단어를 띄어쓰기 단위로 구분하여 숫자를 세는 방식일 것이다. 하지만 한국어 특성상 어절 단위로 띄어쓰기가 이루어져 정확한 키워드 구분이 어렵다. 또한, 한 사람이 반복적으로 같은 단어를 많이 사용하여 워드 클라우드를 왜곡할 수 있다. 이를 방지하기 위해 NLP 라이브러리를 찾았고, KR-WordRank가 어느 정도 해결책이 되었다. 이외에 다양한 라이브러리가 있으나, 배포 편의를 위해 이를 선택했다.
KR-WordRank는 한국어 비지도학습 특징을 고려한 NLP 라이브러리이다. 따라서 한국어 토큰화 문제를 기본적으로 고려하며, HITS 알고리즘 아이디어로 다양한 글에서 반복되는 단어에 높은 가중치를 부여한다. 이는 하나의 글에서 반복적으로 사용되는 단어가 높게 가중치가 부여되는 것을 막을 수 있다. 이 정도만 알고 있어도 이를 이용하여 아래 코드를 구현하는 데는 문제가 없다. KR-WordRank의 원리를 자세히 알고 싶은 분은 여기 글을 추천한다.
🔹 개발 환경
사용한 전체 개발 환경은 다음과 같다.
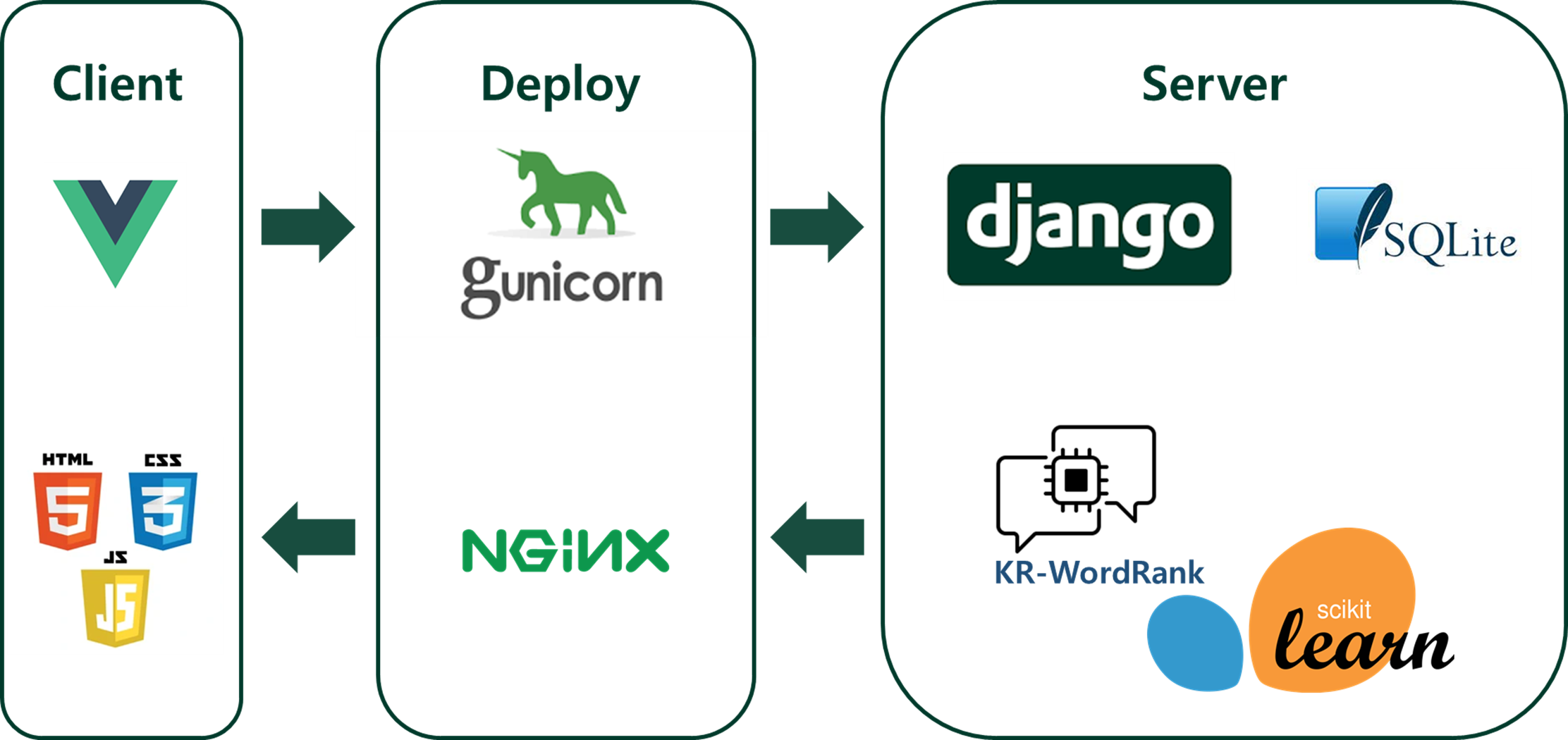
주제와 관련된 Vue.js와 django & KR-WordRank에 집중하여 이야기하겠다.
사용 버전
- django 3.2.7
- Vue.CLI 4.5.15
- Python 3.9.6
패키지
- Django REST framework (https://www.django-rest-framework.org/)
- KR-WordRank (https://github.com/lovit/KR-WordRank)
- VueWordCloud (https://www.npmjs.com/package/vuewordcloud)
🔹 코드 짜기
django
django의 MTV패턴을 알고 있다는 가정하에 설명합니다.
아래는 model, url, view의 핵심 부분 코드이다.
모델은 한 개의 영화에는 N개의 리뷰가 달려있다고 이해할 수 있다.
View는 요청받은 영화의 모든 리뷰를 불러와 input type에 맞게 리스트로 전환한다.
다음 krwordrank를 통해 키워드를 추출한 뒤에 client가 사용할 형태로 변환하여 응답을 보낸다.
### models.py
class Review(models.Model):
...
movie = models.ForeignKey(Movie, on_delete=models.CASCADE) # 영화를 참조함
content = models.CharField(max_length=2000, blank=True) # 리뷰 내용
### urls.py
urlpatterns = [
...
path('movie/<int:movie_id>/review/wordcloud/', views.review_wordcloud),
] # 본 프로젝트는 영화별 리뷰를 다뤘기때문에 movie_id만을 요구
### views.py
from rest_framework.decorators import api_view
from rest_framework.response import Response
from krwordrank.word import summarize_with_keywords
from .models import Review, Movie
@api_view(['GET'])
def review_wordcloud(request, movie_id):
movie = Movie.objects.get(id=movie_id)
all_reviews = movie.review_set.all() # 해당 영화 모든 리뷰
texts = []
for review in all_reviews: # 데이터 전처리
texts.append(review.content)
stopwords = {'영화', '관람객', '너무', '정말', '보고', '일부', '완전히'} # 불용어
keywords = summarize_with_keywords(texts, min_count=3, max_length=10, # NLP
beta=0.85, max_iter=10, stopwords=stopwords, verbose=True)
wordlist = []
count = 0
for key, val in keywords.items(): # 다음 라이브러리를 위한 후처리
temp = {'name': key, 'value': int(val*100)}
wordlist.append(temp)
count += 1
if count >= 30: # 출력 수 제한
break
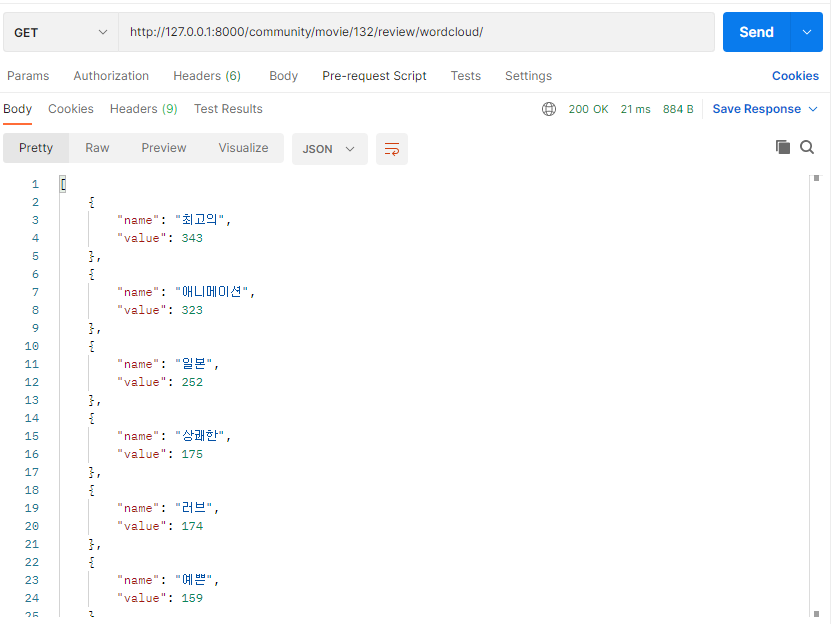
return Response(wordlist)이런 형태로 응답이 보내진다.
Vue.js
위 형태로 응답받은 리스트를 vue-wordcloud 라이브러리 안내대로 넣으면 바로 워드 클라우드가 출력되는 것을 볼 수 있다. 프로젝트 스타일에 맞게 글자색과 배경색을 조절할 수 있다.
<!-- template 내부 -->
<div v-if="defaultWords.length">
<wordcloud
:data="defaultWords"
nameKey="name"
valueKey="value"
:color="myColors"
:showTooltip="false"
:wordClick="wordClickHandler">
</wordcloud>
</div>
<script>
import axios from 'axios'
import wordcloud from 'vue-wordcloud'
export default {
data : function(){
return {
myColors: ['#793c3c', '#E1B4B4', '#DB6E6E', '#A85454'],
defaultWords: [
]
}
},
methods : {
getWorldCloud: function(){
const url = SERVER_URL + '/community/movie/' + this.movie.id + '/review/wordcloud/'
axios({
method: 'get',
url: url,
})
.then(res => {
this.defaultWords = res.data
})
.catch(err => {
console.log(err)
})
}
}
}
</script>
🔹 성능 평가
결과물 관점
리뷰의 개수를 늘려가면서 얼마나 키워드를 잘 담는지 확인하였다.
리뷰가 증가할수록 단어 상태가 점점 괜찮아지며, 어느 정도 의미 없는 키워드가 섞이지만 리뷰의 중심 내용 파악은 가능해 보인다. 테스트용 리뷰는 네이버 영화 리뷰를 사용하였다.
불용어(stopwords)와 파라미터 값을 조절해서 더 알맞게 만들 수 있겠지만, 다른 개발 파트도 많기 때문에 이 정도로 만족하고 넘어간다. 불용어와 파라미터는 출력되는 결과물을 보며 조금씩 수정하면서 맞췄다.

속도 관점
로컬 개발 환경에서 Postman으로 데이터를 늘려가며 속도를 측정했는데 데이터 수에 따른 큰 차이가 없었다. Postman 속도만 비교할 때 페이지 전체를 응답받는데 워드 클라우드가 차지하는 파이는 10% 이하로 괜찮아 보인다. 하지만 본 측정은 100개의 리뷰까지만 진행한 것으로 데이터가 커진 환경을 보장하지 않는다.
🔹 후기
AI를 통해 데이터를 처리하고 결과를 얻는 과정은 주로 jupyter notebook에서 수행해왔다. 이번에 웹 개발을 위해 VS code에서 python 파일을 이용하려 하니 테이블을 생성하는 것부터 배포까지 하나하나 고민할 요소가 많음을 느꼈다. 또한 이전에는 결과의 정확도를 매우 신경 썼다면, 지금은 서비스를 위해 적당한 시기에 개발을 마감해야 하며 서버 전송 시간은 어떨지 등 이전과 다른 고민이 많았다. 개발 목적이 달라지면서 접근 방법이 완전 달라지는 것을 느낄 수 있었던 재밌는 과정이었다.
Ref.
'Programming > AI' 카테고리의 다른 글
| [AWS CodeWhisperer] JetBrains IDE 연동 및 사용 방법 (IntelliJ, PyCharm ...) (0) | 2023.10.02 |
|---|---|
| [AWS CodeWhisperer] Visual Studio Code 연동 및 사용 방법 (0) | 2023.10.02 |
| [Hugging Face API] 허깅페이스 API key 발급 및 여러 모델 사용 예제 (0) | 2023.09.09 |
| [django에 AI 더하기] MySQL 데이터 Pandas Dataframe으로 가져오기 (0) | 2022.05.29 |
| [django에 AI 더하기] sklearn을 이용한 콘텐츠 기반 추천 (0) | 2021.12.01 |








